
- 06 giu 2025
Dalle Radici di ARPANET al Web Moderno: la Storia dell’Inizio di Internet
Cosa impareremo oggi
- La nascita di Internet: il viaggio da ARPANET all'Internet moderno.
- L'evoluzione del web: come ARPANET è diventato Internet.
- Le basi sulle quali si poggia Internet.

Cosa c'è "dietro" le pagine web che visitiamo ogni giorno?
Tutto è iniziato non con i social network o i motori di ricerca, ma con un'esigenza molto specifica: comunicare durante una guerra. Negli anni '60, mentre il mondo era nel pieno della Guerra Fredda, il governo americano voleva creare una rete di comunicazione che fosse indistruttibile, anche sotto attacco nucleare. E così nacque ARPANET. Era come una versione primitiva di Internet, pensata per risolvere un problema molto concreto.
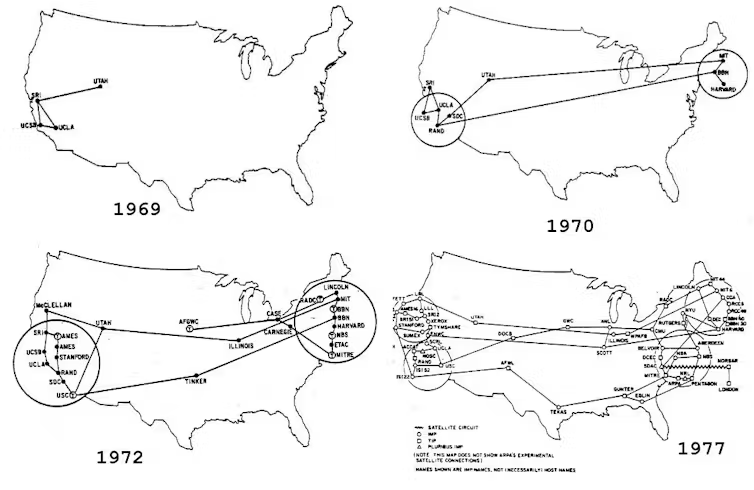
Come funzionava ARPANET e la trasmissione dei dati
ARPANET utilizzava un sistema di commutazione di pacchetto (packet switching), un concetto rivoluzionario all'epoca, che ha gettato le basi per la moderna trasmissione di dati su Internet.
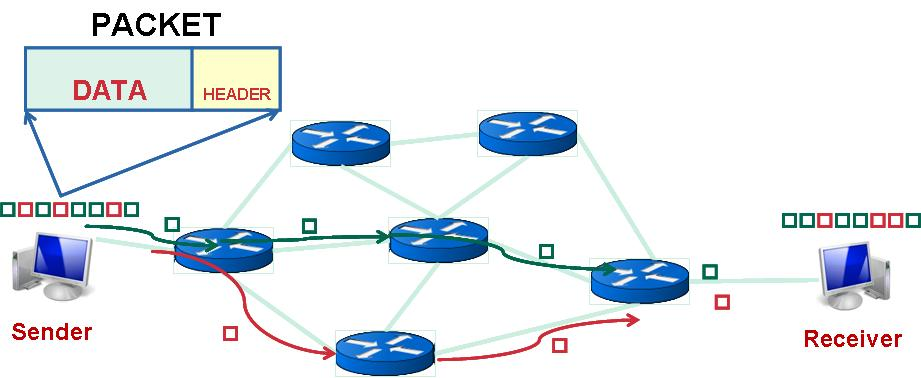
Principio base della commutazione di pacchetto
- Divisione dei dati: I dati venivano suddivisi in piccoli blocchi chiamati pacchetti. Ogni pacchetto conteneva:
- Una parte del contenuto (payload).
- Informazioni di intestazione (header), come l'indirizzo di destinazione.
- Trasmissione indipendente: Ogni pacchetto veniva inviato in modo indipendente attraverso la rete, scegliendo i percorsi disponibili. Non esisteva un percorso fisso.
- Riassemblaggio: Quando i pacchetti arrivavano alla destinazione, venivano riassemblati nell'ordine corretto per ricostruire i dati originali.
ARPANET: elementi chiave
- Ogni computer collegato ad ARPANET era chiamato host.
- I dati passavano attraverso dei nodi intermedi.
- Questo protocollo forniva una connessione peer‑to‑peer tra host, permettendo loro di scambiare file o eseguire programmi a distanza.
- Non c'era una struttura "leggibile" per l'utente: era solo uno scambio di dati binari o testuali tra computer.
- L’esperienza utente era simile a quella che si ha oggi con un prompt dei comandi (command line interface).
Da rete militare a uso civile: la nascita del World Wide Web
Negli anni '80, ARPANET si espanse oltre l'ambito militare, iniziando a collegare università e centri di ricerca per facilitare lo scambio di dati. Tuttavia, queste reti, pur efficienti nel loro contesto, erano limitate geograficamente e tecnologicamente.
Collegamento con l’Europa
Con la diffusione delle reti, emerse la necessità di collegare continenti diversi. Questo fu reso possibile grazie ai cavi sulle dorsali oceaniche, ossia cavi sottomarini posati sul fondo dell'Atlantico per trasmettere dati digitali. Negli anni '70 e '80, questi cavi permisero ad ARPANET di estendere la propria portata oltre i confini degli Stati Uniti, collegando università e istituti di ricerca in Europa, tra cui il CERN di Ginevra. Questo passaggio fu fondamentale per trasformare ARPANET da rete locale a una vera rete di reti, il precursore di Internet.
Il problema al CERN
Nonostante la connessione con ARPANET e altre reti, il CERN, il più grande laboratorio di fisica al mondo, si trovava ad affrontare un problema interno: la mancanza di un sistema unificato per accedere e condividere i dati. Gli scienziati lavoravano su esperimenti globali e utilizzavano reti diverse, ma il trasferimento di dati richiedeva spesso supporti fisici come dischi magnetici, creando inefficienze.
ARPANET quindi permetteva di trasferire dati (file o messaggi), ma non forniva un modo intuitivo per navigare o organizzare le informazioni.

La nascita del World Wide Web
Nel 1989, Tim Berners‑Lee, un informatico britannico del CERN, propose una soluzione per risolvere questo problema: il World Wide Web. La sua idea era di utilizzare un sistema basato sugli ipertesti, in cui documenti potevano essere collegati tra loro tramite link, consentendo un accesso rapido e organizzato alle informazioni.

Per realizzare questa visione, sviluppò tre strumenti chiave:
- HTML (HyperText Markup Language): un linguaggio per strutturare le informazioni.
- HTTP (HyperText Transfer Protocol): un protocollo unico, con delle regole specifiche, per trasferire i documenti.
- Il primo browser: un programma per navigare tra i contenuti, Nexus, precursore dei browser moderni come Google Chrome.
Questa innovazione trasformò Internet da un sistema tecnico e limitato a una risorsa globale accessibile a tutti. Il World Wide Web non solo risolse i problemi di comunicazione al CERN, ma cambiò il modo in cui il mondo intero condivide e utilizza le informazioni. Fu il primo passo per creare una rete di reti, quello che oggi noi chiamiamo Internet.

La rete di reti
Nella nostra navigazione online, oggi frequentiamo una piccolissima parte di questa rete di reti. Ci limitiamo infatti a cercare su dei motori di ricerca e a cliccare sui risultati. Tuttavia, quello che fa il motore di ricerca di turno, come Google, è semplicemente scorrere l’intero Internet e indicizzarlo.
Indicizzazione
L’indicizzazione è il processo con cui un motore di ricerca, come Google, analizza e organizza il contenuto delle pagine web per renderle facilmente accessibili agli utenti. Quando un motore di ricerca "scorre" Internet, utilizza programmi chiamati crawler (o spider), che navigano da una pagina all’altra seguendo i link. Ogni pagina visitata viene analizzata, e il suo contenuto – testo, immagini, video e link – viene classificato e archiviato in un vasto database.
Questo database è ciò che consente al motore di ricerca di rispondere rapidamente alle richieste degli utenti. Quando digitiamo una query, il motore di ricerca non esplora l'intero web in tempo reale, ma consulta il suo indice, una sorta di enorme catalogo, per trovare le pagine più pertinenti. È grazie a questo indice che possiamo ottenere risultati in pochi millisecondi.
L'indicizzazione, quindi, non significa "salvare Internet", ma organizzarne una rappresentazione strutturata che rende possibile l'accesso rapido e mirato alle informazioni.
Ecco un esempio di una pagina web che sicuramente non è indicizzata su Google ma comunque raggiungibile: http://196.202.217.194:8081/
In questo esempio possiamo non solo notare che non è necessario essere su Google per esistere su Internet, ma anche che non è necessario un nome leggibile da un essere umano: bastano i numeri che definiscono l’indirizzo IP della risorsa.

L'indirizzo IP (Internet Protocol) è un identificatore univoco assegnato a ogni dispositivo connesso a una rete. È essenziale per il funzionamento di Internet, perché permette ai dispositivi di comunicare tra loro.
Ci sono due versioni principali di indirizzi IP:
- IPv4: Il formato più comune, composto da quattro numeri separati da punti (ad esempio, 192.168.1.1). Tuttavia, lo spazio di indirizzi IPv4 è limitato.
- IPv6: Introdotto per risolvere il problema della scarsità di IPv4, è molto più lungo e può contenere un numero praticamente illimitato di indirizzi.
Evoluzione della comunicazione: il modello odierno principale
Sebbene modelli di comunicazione peer‑to‑peer esistano ancora e siano largamente diffusi (ad esempio, i torrent), oggi sul web il protocollo di comunicazione più usato è HTTP.
Il World Wide Web (WWW) utilizza appunto HTTP.
Prova di questo la possiamo trovare in qualsiasi sito web, ad esempio https://www.google.com/
Esempio pratico
- ARPANET: Come un gruppo di amici che si scambiano bigliettini direttamente tra loro. Ogni amico può inviare o ricevere informazioni da qualsiasi altro, senza ruoli specifici (modello peer‑to‑peer).
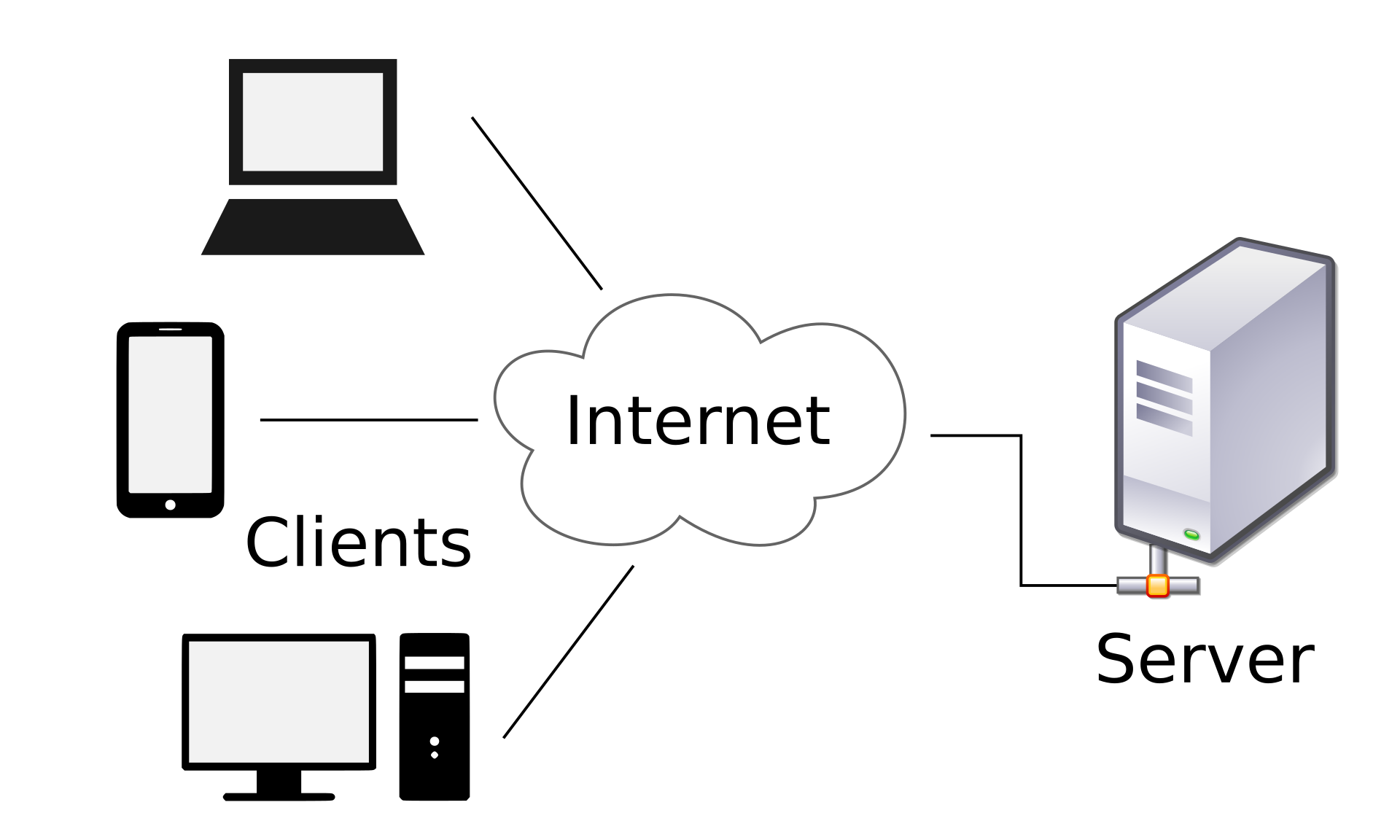
- WWW: Come un ristorante in cui il cameriere (server) riceve le richieste dei clienti (client) e porta loro i piatti richiesti dalla cucina. Qui i ruoli sono chiari: i clienti chiedono (richiesta), e il cameriere serve (risposta).
Curiosità storica
- Il primo sito web di Tim Berners‑Lee spiegava... cos’è il World Wide Web! (visita la pagina originale)
- Il primo server "moderno" della storia di Internet era ospitato al CERN, conteneva il sito sopraccitato ed aveva un’etichetta: «Questa macchina è un server! NON SPEGNERE»

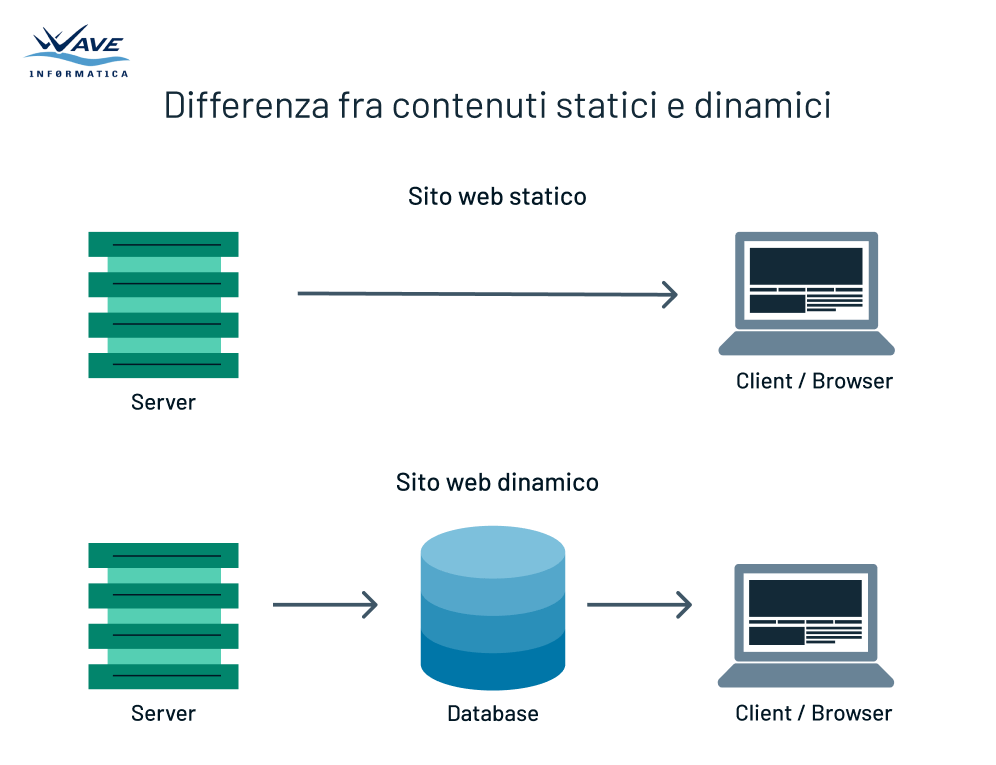
Siti statici: il piatto già pronto
Cosa sono: Pagine web preconfezionate e immutabili. Ogni volta che un cliente fa una richiesta, il server restituisce sempre lo stesso contenuto.
Come funzionano:
- Sono file già scritti in HTML, CSS e, a volte, JavaScript.
- Non cambiano in base alle preferenze o alle richieste dell'utente.
Esempio: Un menu cartaceo del ristorante: il contenuto è sempre lo stesso per tutti i clienti.
Pro: Veloci da caricare, più semplici da realizzare.
Contro: Non interattivi e poco flessibili per contenuti complessi.
Siti dinamici: il piatto personalizzato
Cosa sono: Pagine web generate al momento in base alla richiesta dell'utente.
Come funzionano:
- Il server utilizza un linguaggio di programmazione (come PHP, Python o Node.js) per generare la pagina dinamicamente.
- Spesso i dati vengono presi da un database per personalizzare il contenuto.
Esempio: Un piatto fatto su ordinazione, preparato in base ai gusti del cliente.
Pro: Interattivi e personalizzati; ideali per applicazioni complesse.
Contro: Più lenti da servire e più complessi da mantenere.
Come comunicano client e server?
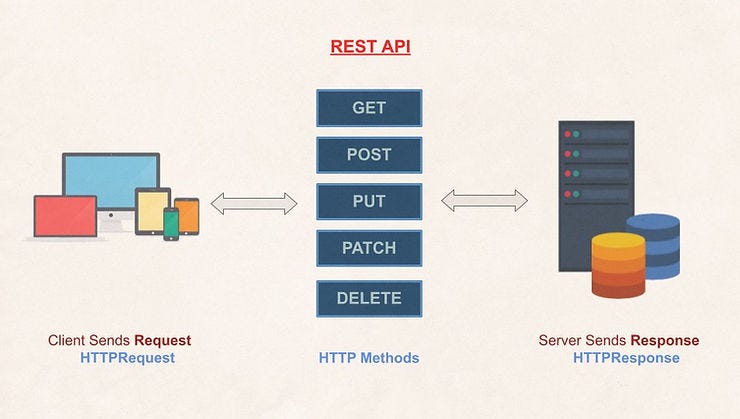
HTTP: Il metodo di comunicazione tra client e server
HTTP è il "linguaggio" che il client (browser) e il server usano per scambiarsi informazioni. Continuando con l'analogia del ristorante:
- La richiesta (Request): Il cliente ordina un piatto al cameriere (server), che segue un formato specifico.
- La risposta (Response): Il cameriere va in cucina, prepara il piatto e lo porta al cliente con un indicatore di stato (ad esempio, 200 OK o 404 Not Found).
I principali metodi HTTP
- GET: "Vorrei vedere il menu." (Richiedere una risorsa).
- POST: "Vorrei ordinare una pizza." (Inviare dati al server).
- PUT: "Vorrei aggiornare la mia ordinazione." (Modificare una risorsa esistente).
- DELETE: "Annulla il mio ordine." (Eliminare una risorsa).
E se l’analogia con la cucina non è abbastanza per spiegare i metodi HTTP, allora ecco dei gattini: HTTP Cats
HTML: Il linguaggio della comunicazione visiva
HTML è la base di qualsiasi sito web. Qualsiasi sito o web app che tu veda online, da Instagram a Facebook, da Google a DigitalBando, è tutto HTML.
Cos’è HTML
- Sta per HyperText Markup Language.
- È un linguaggio di marcatura, non di programmazione, che definisce la struttura di una pagina web.
- HTML utilizza tag per indicare la natura di ogni parte del contenuto.
Struttura di base di un documento HTML
<!DOCTYPE html>
<html>
<head>
<title>Il mio primo sito</title>
</head>
<body>
<h1>Benvenuto!</h1>
<p>Questa è una pagina web scritta in HTML.</p>
<a href='https://esempio.com'>Clicca qui per saperne di più</a>
</body>
</html>Cosa significano le parti principali?
- <!DOCTYPE html> – Indica al browser che il file è un documento HTML5.
- <html> – Racchiude tutto il contenuto della pagina.
- <head> – Contiene meta‑informazioni, come il titolo della pagina.
- <title> – Il titolo che compare nella scheda del browser.
- <body> – La parte visibile della pagina.